Strojno učenje : Pogojna verjetnost in Bayesova teorija, praktična uporaba v produktih Micro Focus

 Verjeli ali ne, strojno učenje ni nikakršen čudež, bavbav ali znanstvena fantastika. Gre se za kombinacijo matematičnih teorij, algebre, statistike ter informacijske teorije. Pa morda še česa. Vse to združujemo v več različnih algoritmov namenjenih reševanju različnih vrst problemov obdelave podatkov. Predvsem obdelave masovnih količin podatkov, torej tam, kjer v osnovi kljub relativno preprostim in razumljivim metodam in algoritmom en človek ali cela armada ljudi zaradi obsega problemov ne more pr iti do rešitve. Vsaj ne pravočasno.
Verjeli ali ne, strojno učenje ni nikakršen čudež, bavbav ali znanstvena fantastika. Gre se za kombinacijo matematičnih teorij, algebre, statistike ter informacijske teorije. Pa morda še česa. Vse to združujemo v več različnih algoritmov namenjenih reševanju različnih vrst problemov obdelave podatkov. Predvsem obdelave masovnih količin podatkov, torej tam, kjer v osnovi kljub relativno preprostim in razumljivim metodam in algoritmom en človek ali cela armada ljudi zaradi obsega problemov ne more pr iti do rešitve. Vsaj ne pravočasno.
V zadnjih letih je strojno učenje postalo zelo popularen izraz. Zakaj? Ravno zato, ker so zmogljivosti strojne opreme in novih algoritmov postale tolikšne, da se lahko implementirajo na masovnih količinah podatkov v rešitvah, katere si lahko privoščijo tudi običajna komercialna podjetja.
Strojno učenje je zelo uporabno na dveh področjih. Prvo je rudarjenja za podatki oz. monetizacija informacij. Drugo je informacijska varnost. Micro Focus ima v ponudbi rešitve iz obeh področij.
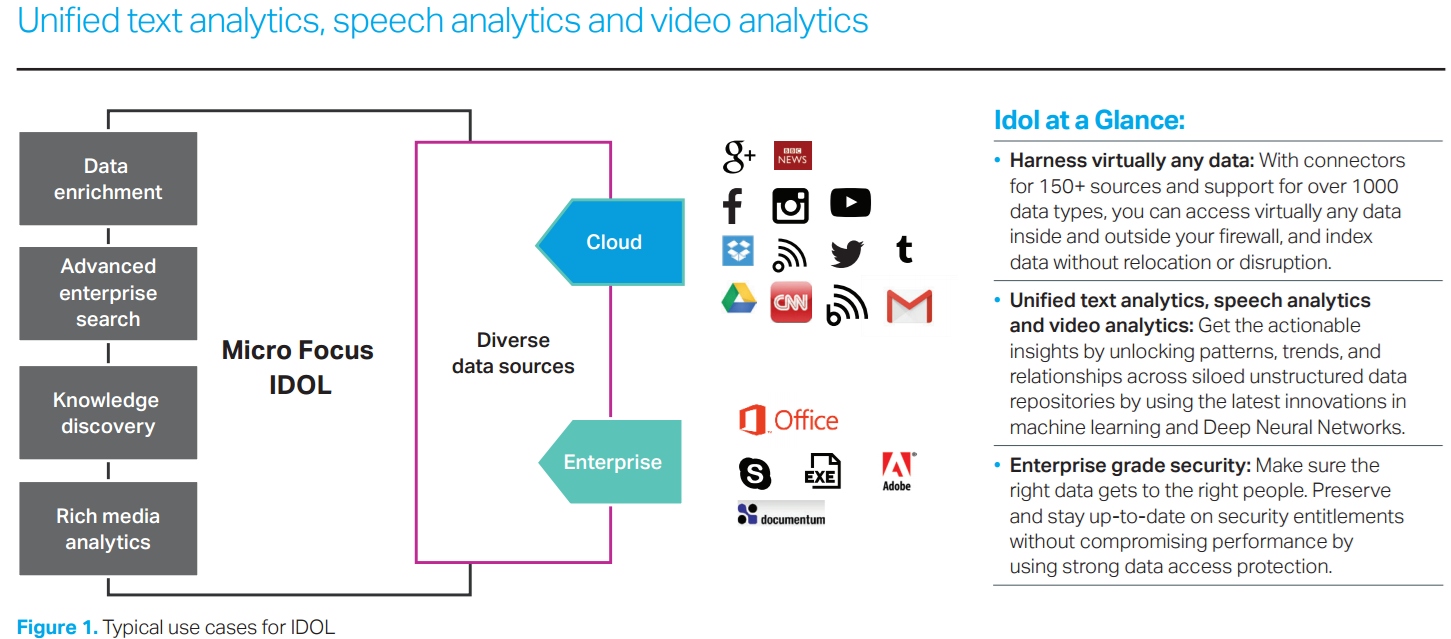
Podatkov je bilo vedno dovolj ali celo preveč, sredstev za pretvoriti jih v poslovno koristne informacije pa nismo imeli. Sedaj jih imamo. Micro Focus Vertica je sistem za zbiranje masovnih podatkov in predvsem za analitične obdelave. Je podatkovna baza, podobno kot Oracle ali MS SQL Server, a posebej razvita iz nule za namene hranjenje in hitrega preiskovanje / analize masovnih podatkov. Vertica vključuje, ob standardnem SQL jeziku in množici analitičnih funkcij iz različnih področij, tudi funkcije za enostavno poganjanje algoritmov strojnega učenja na strukturiranih podatkih. Na drugi strani je Micro Focus IDOL – nabor storitev za obdelavo nestrukturiranih podatkov. Z IDOL-o lahko pridobimo vse mogoče rezultate iz slik, video in avdio posnetkov, teksta, pisarniških ali PDF dokumentov, iz objav na družbenih omrežjih, itn.
Strojno učenje je pomembno tudi rešitvah informacijske varnosti kot so Micro Focus Investigate, User Behavior Analytics (UBA) ali Enterprise Security Manager (ESM). Algoritmi strojnega učenja so namreč najbolj zmogljivo orodje za prepoznavanje vzorcev v podatkih. Predvsem za hitro prepoznavanje vzorcev na veliki količini podatkov. V področju informacijske varnosti lahko odkrivamo potencialne grožnje ali že sprožene napade ravno na podlagi prepoznavanja vzorcev. Seveda ne govorimo o enostavnih, znanih vzorcih, kot so vzorci škodljive kode v proti-virusnih rešitvah, temveč o prepoznavanju še neznanih vzorcev. Še pred nekaj leti je bila strojna oprema prepočasna, da bi lahko te algoritme uporabljali v varnostnih rešitvah v real-time ali near-real-time okolju.
Dovolj reklame … namen tega članka je informiranje o tehnologijah strojnega učenja.

Med našimi zapiski imamo tudi nekaj besed oz. pojasnilo o morda najbolj osnovnem algoritmu strojnega učenja – linearni regresija – katerega bomo morda tudi u redili, da bo primeren za objavo. Tukaj razpravljamo o Bayesovi teoriji, teoremu, inverzni ali pogojni verjetnosti.
Bayesova teorija izvira iz 18st, Thomas Bayes (1701-1761) je bil matematični teoretik, pravzaprav statistik, in filozof. Teorija temelji na njegovem – Bayesovem teoremu, ki je njegov najbolj znani dosežek, katerega pravzaprav sam ni nikoli objavil, v javnost je prišel šele po njegovi smrti.
Teorem predstavlja rešitev problema inverzne verjetnost, čeprav danes več tega izraza ne uporabljamo. Danes uporabljamo samo izraz pogojna verjetnost, problem inverzne verjetnosti oz. rešitev pa je izpeljana iz pogojne verjetnosti.
Inverzna verjetnost je precej povezana s statističnimi metodami in strojnim učenjem. Najpreprostejše metode strojnega učenja temeljijo na »normalni verjetnosti«. Recimo pri tako rekoč najbolj »enostavnem« algoritmu strojnega učenja – linearna regresija – opazujemo eno ali več spremenljivk, ki vsaka od njih vplivajo na nek dogodek. Ko imamo nekaj naborov vrednosti spremenljivk in rezultatov – dogodkov, lahko s postopkom linearne regresije za vsak drug nabor vrednosti spremenljivk predvidevamo, kateri dogodek je najbolj verjeten pri tej kombinaciji spremenljivk.
Primer. Zelo poenostavljen, morda niti ne zelo realen, a dovolj za nas. Kmetovalec goji feferone. Zanima ga, koliko jih bo vzgojil na znani površini zemlje z znanim številom sadik. Tekom vsake sezone si zapomni povprečno dnevno in nočno temperaturo, število sončnih dni in količino padavin. Stotisoč kmetovalcev iz vsega sveta vnaša te podatke v skupno podatkovno bazo z analitičnimi funkcijami, recimo Vertica. Vertica lahko že naslednje leto po manj kot polovici obdobja rasti glede na dotedanje vrednosti teh štirih spremenljivk z veliko natančnostjo napove, kolik bo globalni letni pridelek, po nekaj letih tudi za vsakega posameznika. Na podlagi linearne regresije.
Inverzna verjetnost »deluje v obratni smeri pogojne verjetnosti«. Bila je eden od mnogih nerešenih problemov statistike in verjetnosti v začetku 18. Stoletja – če poznamo končni rezultat, kakšna je verjetnostna distribucija neznane spremenljivke? Na prvi pogled se nam to zdi nepomembno, a v resnici ljudje zelo pogosto če ne vedno delujemo oz. razmišljamo na ta način. Ves čas opazujemo svet okoli sebe, vidimo dogodke, in poskušamo prepoznati pogoje, vzorce, druge dogodke, ki so jih povzročili. Zakaj? Da se lahko bolje pripravimo na prihodnje podobne situacije – vreme, promet, ekonomija, čakalna doba pri zdravniku, itd…
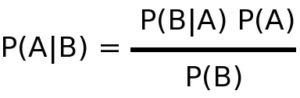
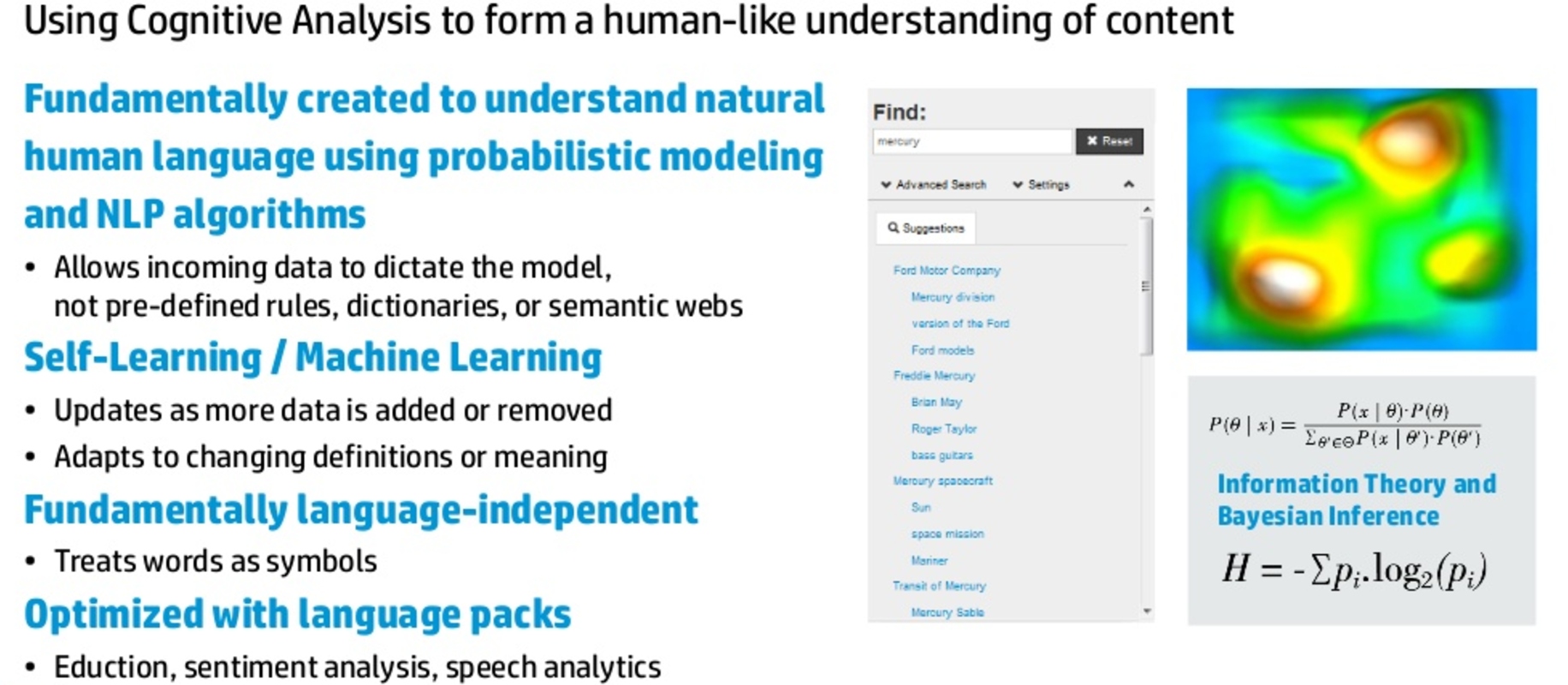
Matematika v ozadju sploh ni tako zapletena. Ta formula na desni, na primer, se nam večini danes, v srednjem življenjskem obdobju, zdi zapletena. Pred leti, v času obiskovanja srednje šole ali univerze, pa nam je bila popolnoma razumljiva, enostavna. Izraz P(A|B) predstavlja pogojno verjetnost, tj. verjetnost, da se je zgodil dogodek A, pod pogojem, da se je zgodil drugi dogodek B.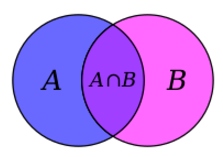
Če formule le nekoliko premečemo, pa lahko dobimo verjetnostno distribucijo za dogodek B, tj. spremenljivko, ki nas zanima, pa smo jo pozabili opazovati. To bi bila inverzna verjetnost. Dogodke lahko prikažemo tudi z množicami, na primer z Vennovim diagramom na levi, ter tudi s formulami vključujoč množice in preseke množic.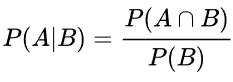
Iz tega izpeljane metode so dandanes zelo pomembne v mnogih področjih računalništva – strojno učenje, umetna inteligenca, ekspertni sistemi. Ter za klasifikacijo in prepoznavanje vzorcev v različnih primerih uporabe, pogosto tudi v področju informacijske varnosti. Večkrat jih zasledimo v razpisih za varnostne rešitve, brez da bi izdajatelji razpisa pravzaprav natančno vedeli, za kaj se sploh gre.
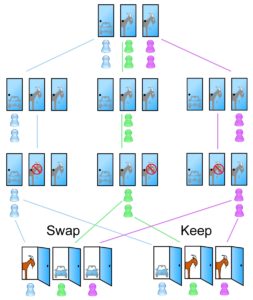 Matematične in statistične metode nas rešujejo iz zagat, kjer človeška intuicija odpove. S pravilno rabo Bayesovega teorema lahko na primer rešimo problem poznan pod imenom »Monty Hall«. Problem temelji na enostavnem komercialnem TV šovu ki poteka takole:
Matematične in statistične metode nas rešujejo iz zagat, kjer človeška intuicija odpove. S pravilno rabo Bayesovega teorema lahko na primer rešimo problem poznan pod imenom »Monty Hall«. Problem temelji na enostavnem komercialnem TV šovu ki poteka takole:
Igralec pride na oder, na katerem je samo voditelj šova in troje zaprtih vrat. Igralec ve, da se za enim od vrat skriva avtomobil, ki je lahko njegova nagrada, za drugima dvema pa ni ničesar (ali v nekaterih variantah – koza). Seveda pa ne ve kaj je skrito za katerimi vrati. Na začetku mu voditelj da možnost izbrati ena vrata, recimo vrata 1. Voditelj, ki ve kaj se skriva za vsemi vrati, mu nato odpre in pokaže kaj je za enimi drugimi vrati, recimo vrati št. 3, medtem ko so tista, ki jih je igralec izbral,m še vedno zaprta. Za odprtimi vrati se skriva – koza. Zviti voditelj nato postavi našega igralca pred dilemo – »Ali želiš spremeniti svojo odločitev?«.
No, kaj bi vi naredili?
Intuicija nam pravi, da je to vseeno. Intuicija nam pravi – samo dvoje vrat je še zaprtih, torej je pol-pol možnosti za vsako od vrat, za tista, ki sem jih že izbral, in za ona druga. S stališča verjetnosti, pravi intuicija, torej menjava odločitve ne bo vplivala na verjetnost zadetke. Pri dveh vratih je verjetnost pol-pol. Ali?
Intuicija nas v tem primeru pusti na cedilu! Z Bayesovim teoremom ugotovimo oz. dokažemo, da si igralec, ki spremeni svojo prvotno odločitev, podvoji verjetnost zadeti avtomobil. Bolj verjetno je, da se avtomobil skriva za vrati, katerih igralec ni izbral na začetku! Rekli bi – čudno, a tako je.
Take metode se lahko uporabljajo pri različnih hazardnih igrah z zaporedjem “naključnih” izbir.
A zakaj sploh pišemo o tem v našem blogu? O igrah, hazardiranju itd? Ker je to osnova ene od metod strojnega učenja.
Ok, omenili smo Micro Focus Vertica, zmogljivo podatkovno bazo za hitre analitične obdelave masovnih količin podatkov. Z njo je enostavno z Bayesovo in drugimi vgrajenimi statističnimi metodami in postopki strojnega učenje, uporabo jezika R, geografskih prostorskih funkcij (geodezija) itd. reševati mnoge probleme obdelave podatkov. Drugi produkt, vezan na Bayesov teorem (in MNOGE druge stvari), je Micro Focus IDOL. In recimo Micro Focus Vertica.
Micro Focus Vertica, primer: Klasifikacija podatkov po metodi Naive Bayes
V Vertici lahko delamo enostavno podatkovno analitiko, tudi z metodami strojnega učenja, za katere bi rekli, da jih zmorejo izvajati samo strokovnjaki. Pa temu niti približno ni tako. Ker so v Vertico že vgrajene funkcije analitike in strojnega učenja, lahko podatke po Bayesovih metodah obdelamo s klicem ene preproste funkcije povpraševanja po podatkih. V tem primeru funkcije PREDICT_NAIVE_BAYES_CLASSES (orig. razlaga vgrajene funkcije: Applies a Naive Bayes model on an input table or view), ki klasificira podatke po metodi Naive Bayes (https://en.wikipedia.org/wiki/Naive_Bayes_classifier).
Poglejmo si en primer iz politike. In da, zavedamo se da zadnje čase podatkovna analitika zaradi afer v politiki ni ravno na dobrem glasu. To ni krivda metod ali orodij, temveč krivda skorumpiranih ljudi, ki so te metode, orodja in podatke zlorabljali.
Za primer vzemimo ameriški parlament. Za namene arhiviranja lahko shranjujemo podatke o glasovanjih za posamezne odločitve. Zaradi varovanja osebnih podatkov mora naš arhiv biti anonimiziran, pomeni, da ne smemo hraniti imen volivcev. V vseh podatkih se pojavljajo samo neke naključno oz. po zaporedju izbrane številke, identifikatorji volivcev.
V bazi že imamo hranjen model, to je zbirka podatkov o volitvah in rezultatih v preteklosti, in še česa drugega, poimenovan – ‘naive_house84_model’. Za kaj bi sedaj lahko uporabili Bayesovo metodo? Ker so podatki anonimizirani, ne vemo imen volivcev, niti ne tega, kdo od njih je demokrat in kdo republikanec. Bayesova metoda deluje v obratni smeri, iz nekega dogodka lahko sklepamo na to kaj je najbolj verjetno, da ga je povzročilo. V našem primeru lahko iz zbirke odločitev volivcev poskušamo sklepati, kateri od njih je demokrat in kateri republikanec. In sicer tako: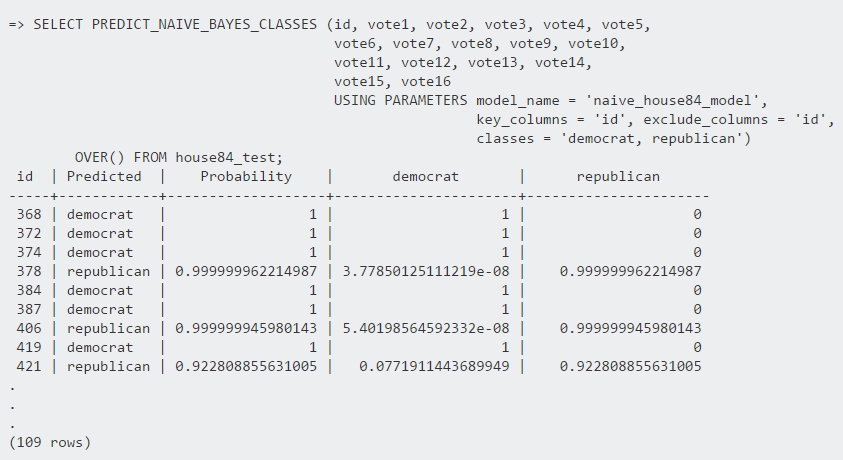
Ta Bayesova metoda se uporablja tudi v anti-spam rešitvah za zmanjševanje napačnih detekcij – false positives.
 V Micro Focus IDOL se Bayesova metoda uporablja za klasifikacijo slik, dokumentov in drugih nestrukturiranih podatkov.
V Micro Focus IDOL se Bayesova metoda uporablja za klasifikacijo slik, dokumentov in drugih nestrukturiranih podatkov.
V IDOL najprej naložimo nekaj vzorčnih slik, s katerimi naš sistem »naučimo« klasifikacije, recimo za klasifikacijo po živalih naložimo nekaj slik mačk, za katere rečemo »to je razred Slike-Živali-Mačke«, in nekaj slik psov, za katere rečemo »To je razred Slike-Živali-Psi«.
IDOL bo potem lahko pregledal na tisoče slik, posnetkov in drugih dokumentov, in jih z določenimi verjetnostmi klasificiral v ta dva razreda. Potem bi lahko grafično prikazali dokumente, ki so z neko verjetnostjo v enem, v drugem, ali v nobenem razredu.
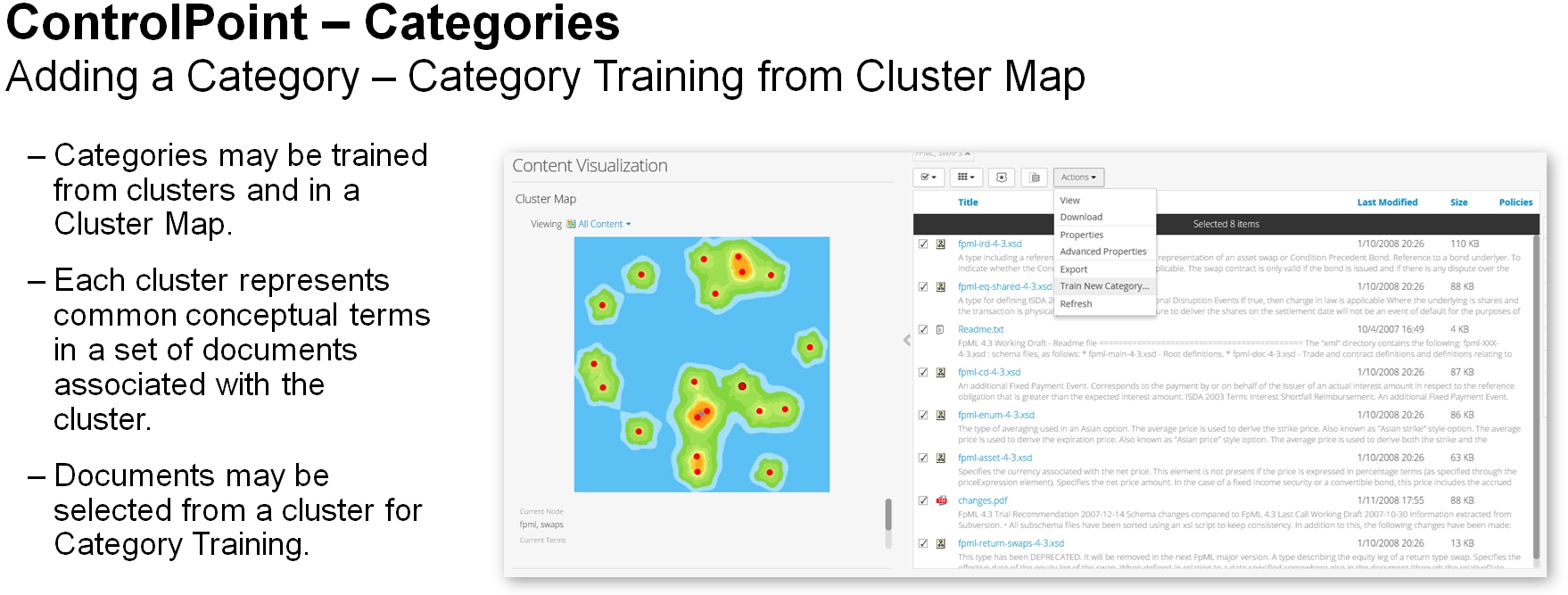
Micro Focus Control Point
IDOL je tudi analitično srce produkta za analizo datotek – nestrukturiranih podatkov – Micro Focus Control Point (CP). V Gartnerju definirajo tržišče aplikacij za analizo datotek – File Analysis Software – kot:
‘Programski izdelki za analiziranje, indeksiranje, preiskovanje, spremljanje in poročanje o vsebinah in meta podatkih datotek. Podjetjem omogočajo kreiranje varnostnih pravilnikov in ukrepanje glede na vrsto podatkov v odkritih datotekah. Orodja zbirajo podrobne meta-podatke in kontekstualne informacije, ki omogočajo podjetjem boljši nadzor informacij in operativno učinkovitost upravljanje nestrukturiranih podatkov. Datotečna analiza je še razvijajoča se vrsta rešitev, sestavljena iz različnih tehnologij, ki lahko pomagajo pri razumevanju naraščajočega obsega nestrukturiranih podatkov vključujoč diskovne sisteme za deljenje datotek, e-poštne arhive, rešitve za sinhronizacijo in deljenje datotek v podjetju in na oddaljene lokacije, produkte za upravljanje z dokumenti in upravljanje vsebin, ter arhive kot so Microsoft SharePoint in drugi arhivi podatkov.‘
Control Point lahko analizira datoteke ne glede na vsebino – tekst, slike, video, zvok, PDF, pisarniški dokumenti. Seveda zahvaljujoč se IDOL-u. In tudi zahvaljujoč se v IDOL vgrajenimi algoritmi strojnega učenja, ki omogočajo odkrivanje vsebin, klasifikacijo datotek na podlagi učenja, odkrivanje osebnih identifikacijskih podatkov za potrebe skladnosti z GDPR itd. CP izkorišča IDOL Connector-je, da lahko razume različne vrste datotečnih repozitorijev in arhivov. CP ni zgolj datotečna analitika, temveč tudi upravljanje datotečnih repozitorijev na podlagi varnostnih pravilnikov, ki jih sestavljamo kar znotraj produkta. Pravilniki določajo akcije nad datotekami, ki se lahko sprožajo na primer ko CP odkrije datoteko ali periodično. Primer – CP naučimo klasificiranja datotek glede na vrsto podatkov v njih, in če je odkrita datoteka klasificirana kot datoteka z osebnimi podatki, se takoj šifrira ali premakne na posebej zaščiten datotečni sistem. Periodični pravilnik pa lahko optimizira vsakodnevno poslovanje tako da na primer briše več kot določeno število let stare datoteke, ali pa jih premakne v za to namenjen arhiv.