

Obfuscated Command Line Detection Using Machine Learning
This blog post presents a machine learning (ML) approach to solving an emerging security problem: detecting obfuscated Windows command line invocations on endpoints. We start out with an introduction to this relatively new threat capability, and then discuss how such problems have traditionally been handled. We then describe a machine learning approach to solving this problem and point out how ML vastly simplifies development and maintenance of a robust obfuscation detector. Finally, we present the results obtained using two different ML techniques and compare the benefits of each.
Introduction
Malicious actors are increasingly “living off the land,” using built-in utilities such as PowerShell and the Windows Command Processor (cmd.exe) as part of their infection workflow in an effort to minimize the chance of detection and bypass whitelisting defense strategies. The release of new obfuscation tools makes detection of these threats even more difficult by adding a layer of indirection between the visible syntax and the final behavior of the command. For example, Invoke-Obfuscation and Invoke-DOSfuscation are two recently released tools that automate the obfuscation of Powershell and Windows command lines respectively.
The traditional pattern matching and rule-based approaches for detecting obfuscation are difficult to develop and generalize, and can pose a huge maintenance headache for defenders. We will show how using ML techniques can address this problem.
Detecting obfuscated command lines is a very useful technique because it allows defenders to reduce the data they must review by providing a strong filter for possibly malicious activity. While there are some examples of “legitimate” obfuscation in the wild, in the overwhelming majority of cases, the presence of obfuscation generally serves as a signal for malicious intent.
Background
There has been a long history of obfuscation being employed to hide the presence of malware, ranging from encryption of malicious payloads (starting with the Cascade virus) and obfuscation of strings, to JavaScript obfuscation. The purpose of obfuscation is two-fold:
- Make it harder to find patterns in executable code, strings or scripts that can easily be detected by defensive software.
- Make it harder for reverse engineers and analysts to decipher and fully understand what the malware is doing.
In that sense, command line obfuscation is not a new problem – it is just that the target of obfuscation (the Windows Command Processor) is relatively new. The recent release of tools such as Invoke-Obfuscation (for PowerShell) and Invoke-DOSfuscation (for cmd.exe) have demonstrated just how flexible these commands are, and how even incredibly complex obfuscation will still run commands effectively.
There are two categorical axes in the space of obfuscated vs. non-obfuscated command lines: simple/complex and clear/obfuscated (see Figure 1 and Figure 2). For this discussion “simple” means generally short and relatively uncomplicated, but can still contain obfuscation, while “complex” means long, complicated strings that may or may not be obfuscated. Thus, the simple/complex axis is orthogonal to obfuscated/unobfuscated. The interplay of these two axes produce many boundary cases where simple heuristics to detect if a script is obfuscated (e.g. length of a command) will produce false positives on unobfuscated samples. The flexibility of the command line processor makes classification a difficult task from an ML perspective.
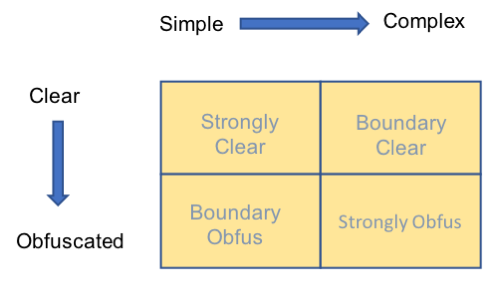
Figure 1: Dimensions of obfuscation

Figure 2: Examples of weak and strong obfuscation
Traditional Obfuscation Detection
Traditional obfuscation detection can be split into three approaches. One approach is to write a large number of complex regular expressions to match the most commonly abused syntax of the Windows command line. Figure 3 shows one such regular expression that attempts to match ampersand chaining with a call command, a common pattern seen in obfuscation. Figure 4 shows an example command sequence this regex is designed to detect.
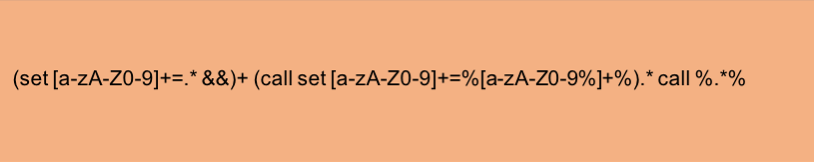
Figure 3: A common obfuscation pattern captured as a regular expression

Figure 4: A common obfuscation pattern (calling echo in obfuscated fashion in this example)
There are two problems with this approach. First, it is virtually impossible to develop regular expressions to cover every possible abuse of the command line. The flexibility of the command line results in a non-regular language, which is feasible yet impractical to express using regular expressions. A second issue with this approach is that even if a regular expression exists for the technique a malicious sample is using, a determined attacker can make minor modifications to avoid the regular expression. Figure 5 shows a minor modification to the sequence in Figure 4, which avoids the regex detection.
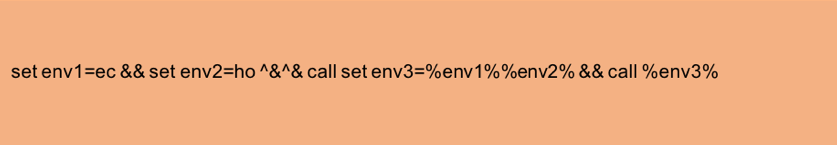
Figure 5: A minor change (extra carets) to an obfuscated command line that breaks the regular expression in Figure 3
The second approach, which is closer to an ML approach, involves writing complex if-then rules. However, these rules are hard to derive, are complex to verify, and pose a significant maintenance burden as authors evolve to escape detection by such rules. Figure 6 shows one such if-then rule.
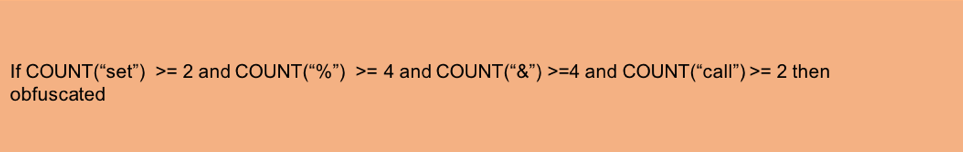
Figure 6: An if-then rule that *may* indicate obfuscation (notice how loose this rule is, and how false positives are likely)
A third approach is to combine regular expressions and if-then rules. This greatly complicates the development and maintenance burden, and still suffers from the same weaknesses that make the first two approaches fragile. Figure 7 shows an example of an if-then rule with regular expressions. Clearly, it is easy to appreciate how burdensome it is to generate, test, maintain and determine the efficacy of such rules.
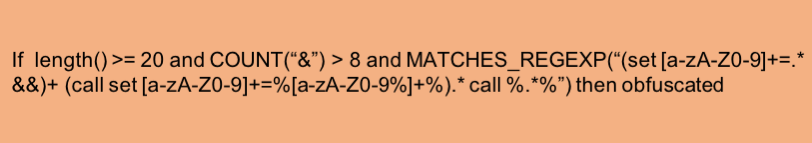
Figure 7: A combination of an if-then rule with regular expressions to detect obfuscation (a real hand-built obfuscation detector would consist of tens or hundreds of rules and still have gaps in its detection)
The ML Approach – Moving Beyond Pattern Matching and Rules
Using ML simplifies the solution to these problems. We will illustrate two ML approaches: a feature-based approach and a feature-less end-to-end approach.
There are some ML techniques that can work with any kind of raw data (provided it is numeric), and neural networks are a prime example. Most other ML algorithms require the modeler to extract pertinent information, called features, from raw data before they are fed into the algorithm. Some examples of this latter type are tree-based algorithms, which we will also look at in this blog (we described the structure and uses of Tree-Based algorithms in a previous blog post, where we used a Gradient-Boosted Tree-Based Model).
ML Basics – Neural Networks
Neural networks are a type of ML algorithm that have recently become very popular and consist of a series of elements called neurons. A neuron is essentially an element that takes a set of inputs, computes a weighted sum of these inputs, and then feeds the sum into a non-linear function. It has been shown that a relatively shallow network of neurons can approximate any continuous mapping between input and output. The specific type of neural network we used for this research is what is called a Convolutional Neural Network (CNN), which was developed primarily for computer vision applications, but has also found success in other domains including natural language processing. One of the main benefits of a neural network is that it can be trained without having to manually engineer features.
Featureless ML
While neural networks can be used with feature data, one of the attractions of this approach is that it can work with raw data (converted into numeric form) without doing any feature design or extraction. The first step in the model is converting text data into numeric form. We used a character-based encoding where each character type was encoded by a real valued number. The value was automatically derived during training and conveys semantic information about the relationships between characters as they apply to cmd.exe syntax.
Feature-Based ML
We also experimented with hand-engineered features and a Gradient Boosted Decision Tree algorithm. The features developed for this model were largely statistical in nature – derived from the presence and frequency of character sets and keywords. For example, the presence of dozens of ‘%’ characters or long, contiguous strings might contribute to detecting potential obfuscation. While any single feature will not perfectly separate the two classes, a combination of features as present in a tree-based model can learn flexible patterns in the data. The expectation is that those patterns are robust and can generalize to future obfuscation variants.
Data and Experiments
To develop our models, we collected non-obfuscated data from tens of thousands of endpoint events and generated obfuscated data using a variety of methods in Invoke-DOSfuscation. We developed our models using roughly 80 percent of the data as training data, and tested them on the remaining 20 percent. We ensured that our train-test split was stratified. For featureless ML (i.e. neural networks), we simply input Unicode code points into the first layer of the CNN model. The first layer converts the code point into semantically meaningful numerical representations (called embeddings) before feeding it into the rest of the neural network.
For the Gradient Boosted Tree method, we generated a number of features from the raw command lines. The following are some of them:
- Length of the command line
- The number of carets in the command line
- The count of pipe symbols
- The fraction of white space in the command line
- The fraction of special characters
- Entropy of the string
- The frequency of the strings “cmd” and “power” in the command line
While each of these features individually is a weak signal and could not possibly be a good discriminator on its own, a flexible classifier such as a Gradient Boosted Tree – trained on sufficient data with these features – is able to classify obfuscated and non-obfuscated command lines in spite of the aforementioned difficulties.
Results
Evaluated against our test set, we were able to get nearly identical results from our Gradient Boosted Tree and neural network models.
The results for the GBT model were near perfect with metrics such as F1-score, precision, and recall all being close to 1.0. The CNN model was slightly less accurate.
While we certainly do not expect perfect results in a real-world scenario, these lab results were nonetheless encouraging. Recall that all of our obfuscated examples were generated by one source, namely the Invoke-DOSfuscation tool. While Invoke-DOSfuscation generates a wide variety of obfuscated samples, in the real world we expect to see at least some samples that are quite dissimilar from any that Invoke-DOSfuscation generates. We are currently collecting real world obfuscated command lines to get a more accurate picture of the generalizability of this model on obfuscated samples from actual malicious actors. We expect that command obfuscation, similar to PowerShell obfuscation before it, will continue to emerge in new malware families.
As an additional test we asked Daniel Bohannon (author of Invoke-DOSfuscation, the Windows command line obfuscation tool) to come up with obfuscated samples that in his experience would be difficult for a traditional obfuscation detector. In every case, our ML detector was still able to detect obfuscation. Some examples are shown in Figure 8.

Figure 8: Some examples of obfuscated text used to test and attempt to defeat the ML obfuscation detector (all were correctly identified as obfuscated text)
We also created very cryptic looking texts that, although valid Windows command lines and non-obfuscated, appear slightly obfuscated to a human observer. This was done to test efficacy of the detector with boundary examples. The detector was correctly able to classify the text as non-obfuscated in this case as well. Figure 9 shows one such example.

Figure 9: An example that appears on first glance to be obfuscated, but isn’t really and would likely fool a non-ML solution (however, the ML obfuscation detector currently identifies it as non-obfuscated)
Finally, Figure 10 shows a complicated yet non-obfuscated command line that is correctly classified by our obfuscation detector, but would likely fool a non-ML detector based on statistical features (for example a rule-based detector with a hand-crafted weighing scheme and a threshold, using features such as the proportion of special characters, length of the command line or entropy of the command line).
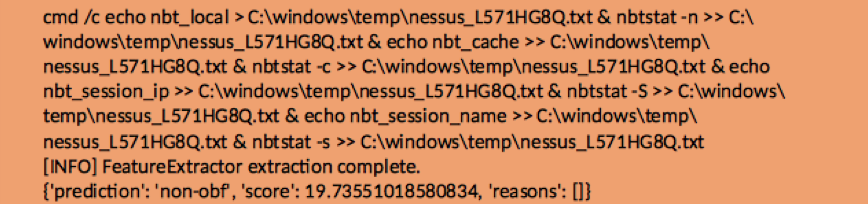
Figure 10: An example that would likely be misclassified by an ML detector that uses simplistic statistical features; however, our ML obfuscation detector currently identifies it as non-obfuscated
CNN vs. GBT Results
We compared the results of a heavily tuned GBT classifier built using carefully selected features to those of a CNN trained with raw data (featureless ML). While the CNN architecture was not heavily tuned, it is interesting to note that with samples such as those in Figure 10, the GBT classifier confidently predicted non-obfuscated with a score of 19.7 percent (the complement of the measure of the classifier’s confidence in non-obfuscation). Meanwhile, the CNN classifier predicted non-obfuscated with a confidence probability of 50 percent – right at the boundary between obfuscated and non-obfuscated. The number of misclassifications of the CNN model was also more than that of the Gradient Boosted Tree model. Both of these are most likely the result of inadequate tuning of the CNN, and not a fundamental shortcoming of the featureless approach.
Conclusion
In this blog post we described an ML approach to detecting obfuscated Windows command lines, which can be used as a signal to help identify malicious command line usage. Using ML techniques, we demonstrated a highly accurate mechanism for detecting such command lines without resorting to the often inadequate and costly technique of maintaining complex if-then rules and regular expressions. The more comprehensive ML approach is flexible enough to catch new variations in obfuscation, and when gaps are detected, it can usually be handled by adding some well-chosen evader samples to the training set and retraining the model.
This successful application of ML is yet another demonstration of the usefulness of ML in replacing complex manual or programmatic approaches to problems in computer security. In the years to come, we anticipate ML to take an increasingly important role both at FireEye and in the rest of the cyber security industry.